Just for fun, let’s see what all this actually means in local coordiantes. It’s a good idea to get our hands dirty too. To me at least, this makes the operators seem somewhat more friendly.
Choose local coordinates 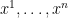 . Let
. Let
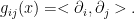
Let  . Note that
. Note that 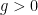 .
.
Henceforth, we will use the Einstein summation convention: all repeated indices are to be summed over, unless otherwise stated. For instance, the inner product is the 2-tensor

Div
Now let 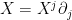 be a vector field. We want to compute
be a vector field. We want to compute 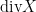 in terms of the quantities
in terms of the quantities  and
and  . First, it will be necessary to compute the form
. First, it will be necessary to compute the form 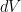 . I claim that, if we take
. I claim that, if we take  to be oriented coordinates, then
to be oriented coordinates, then
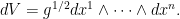
We will prove a more general fact. Whenever  is an oriented basis for the cotangent space (not necessarily orthonormal), and
is an oriented basis for the cotangent space (not necessarily orthonormal), and  , is defined as before:
, is defined as before:

Indeed, this is clear when is orthonormal. And it is clear that the above quantity is actually invariant under changes of frame—this is a fact of linear algebra.
So now, with this we can tackle the problem of computing . We have:
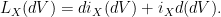
I’m not terribly thrilled with this notation. looks like the exterior differential of some  , which it is not. However, this seems to be the norm. Anyhow,
, which it is not. However, this seems to be the norm. Anyhow,  is zero, not because
is zero, not because 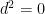 , but rather because is an
, but rather because is an  -form. As a result, we are reduced to computing
-form. As a result, we are reduced to computing 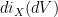 , which turns out to be rather straightforward. First of all:
, which turns out to be rather straightforward. First of all:
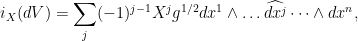
by definition of how the wedge product works and the interior product. (I guess this is not completely standard. If you use a different definition, you’d get a constant factor added.) Now if we apply  to this we find:
to this we find:

and as a result:
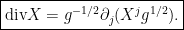
From this the property  is clear, since
is clear, since 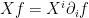 .
.
Incidentally, to say that 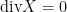 is to say that the flows of
is to say that the flows of  preserve the volume, so it makes sense to call incompressible.
preserve the volume, so it makes sense to call incompressible.
Grad
Now we want to do the same for  . First,
. First, 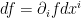 . The transformation of a vector
. The transformation of a vector 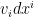 to
to 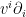 works by
works by 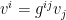 , where
, where 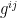 is the inverse of the matrix
is the inverse of the matrix  , I claim. This can be seen as follows:
, I claim. This can be seen as follows:

What this rather uninspiring statement means is that 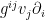 acts as functional on the tangent space via the inner product in the same way that the cotangent vector does. In particular, it proves the claim I just made. (Cf. also the Wikipedia article on raising and lowering indices.) So
acts as functional on the tangent space via the inner product in the same way that the cotangent vector does. In particular, it proves the claim I just made. (Cf. also the Wikipedia article on raising and lowering indices.) So
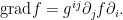
The Laplacian
Finally, as a result, we can get the representation of  in local coordinates:
in local coordinates:
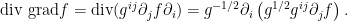
In particular, we find that  as an operator is
as an operator is 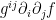 plus something solely first order. Since is a positive-definite matrix, this will imply (I will later define this) that the Laplacian is an elliptic operator.
plus something solely first order. Since is a positive-definite matrix, this will imply (I will later define this) that the Laplacian is an elliptic operator.

January 12, 2010 at 1:38 pm
You can go in the following link http://anhngq.wordpress.com/2009/11/26/r-g-hessian-and-laplacian/
January 12, 2010 at 3:48 pm
Nice blog!